- ASCII
-
 Hay 95 caracteres ASCII imprimibles, numerados del 32 al 126.
Hay 95 caracteres ASCII imprimibles, numerados del 32 al 126.ASCII (acrónimo inglés de American Standard Code for Information Interchange — Código Estándar Americano para el Intercambio de Información), pronunciado generalmente [áski] o [ásci] , es un código de caracteres basado en el alfabeto latino, tal como se usa en inglés moderno y en otras lenguas occidentales. Fue creado en 1963 por el Comité Estadounidense de Estándares (ASA, conocido desde 1969 como el Instituto Estadounidense de Estándares Nacionales, o ANSI) como una refundición o evolución de los conjuntos de códigos utilizados entonces en telegrafía. Más tarde, en 1967, se incluyeron las minúsculas, y se redefinieron algunos códigos de control para formar el código conocido como US-ASCII.
El código ASCII utiliza 7 bits para representar los caracteres, aunque inicialmente empleaba un bit adicional (bit de paridad) que se usaba para detectar errores en la transmisión. A menudo se llama incorrectamente ASCII a otros códigos de caracteres de 8 bits, como el estándar ISO-8859-1 que es una extensión que utiliza 8 bits para proporcionar caracteres adicionales usados en idiomas distintos al inglés, como el español.
ASCII fue publicado como estándar por primera vez en 1967 y fue actualizado por última vez en 1986. En la actualidad define códigos para 33 caracteres no imprimibles, de los cuales la mayoría son caracteres de control obsoletos que tienen efecto sobre cómo se procesa el texto, más otros 95 caracteres imprimibles que les siguen en la numeración (empezando por el carácter espacio).
Casi todos los sistemas informáticos actuales utilizan el código ASCII o una extensión compatible para representar textos y para el control de dispositivos que manejan texto como el teclado. No deben confundirse los códigos ALT+número de teclado con los códigos ASCII.
Contenido
Vista general
Las computadoras solamente entienden números. El código ASCII es una representación numérica de un carácter como ‘a’ o ‘@’.[1]
Como otros códigos de formato de representación de caracteres, el ASCII es un método para una correspondencia entre cadenas de bits y una serie de símbolos (alfanuméricos y otros), permitiendo de esta forma la comunicación entre dispositivos digitales así como su procesado y almacenamiento. El código de caracteres ASCII[2] —o una extensión compatible (ver más abajo)— se usa casi en todos los ordenadores, especialmente con ordenadores personales y estaciones de trabajo. El nombre más apropiado para este código de caracteres es "US-ASCII".[3]
-
- ! " # $ % & ' ( ) * +, -. / 0 1 2 3 4 5 6 7 8 9 :; < = > ?
- @ A B C D E F G H I J K L M N O P Q R S T U V W X Y Z [ \ ] ^ _
- ` a b c d e f g h i j k l m n o p q r s t u v w x y z { | } ~
ASCII es, en sentido estricto, un código de siete bits, lo que significa que usa cadenas de bits representables con siete dígitos binarios (que van de 0 a 127 en base decimal) para representar información de caracteres. En el momento en el que se introdujo el código ASCII muchos ordenadores trabajaban con grupos de ocho bits (bytes u octetos), como la unidad mínima de información; donde el octavo bit se usaba habitualmente como bit de paridad con funciones de control de errores en líneas de comunicación u otras funciones específicas del dispositivo. Las máquinas que no usaban la comprobación de paridad asignaban al octavo bit el valor cero en la mayoría de los casos, aunque otros sistemas como las computadoras Prime, que ejecutaban PRIMOS ponían el octavo bit del código ASCII a uno.
El código ASCII define una relación entre caracteres específicos y secuencias de bits; además de reservar unos cuantos códigos de control para el procesador de textos, y no define ningún mecanismo para describir la estructura o la apariencia del texto en un documento; estos asuntos están especificados por otros lenguajes como los lenguajes de etiquetas.
Historia
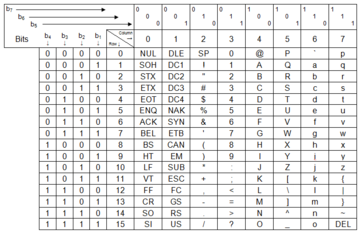 La carta de Código ASCII 1968 de los E.E.U.U. fue estructurada con dos columnas de caracteres de control, una columna con caracteres especiales, una columna con números, y cuatro columnas de letras
La carta de Código ASCII 1968 de los E.E.U.U. fue estructurada con dos columnas de caracteres de control, una columna con caracteres especiales, una columna con números, y cuatro columnas de letras
El código ASCII se desarrolló en el ámbito de la telegrafía y se usó por primera vez comercialmente como un código de teleimpresión impulsado por los servicios de datos de Bell. Bell había planeado usar un código de seis bits, derivado de Fieldata, que añadía puntuación y letras minúsculas al más antiguo código de teleimpresión Baudot, pero se les convenció para que se unieran al subcomité de la Agencia de Estándares Estadounidense (ASA), que habían empezado a desarrollar el código ASCII. Baudot ayudó en la automatización del envío y recepción de mensajes telegráficos, y tomó muchas características del código Morse; sin embargo, a diferencia del código Morse, Baudot usó códigos de longitud constante. Comparado con los primeros códigos telegráficos, el código propuesto por Bell y ASA resultó en una reorganización más conveniente para ordenar listas (especialmente porque estaba ordenado alfabéticamente) y añadió características como la 'secuencia de escape'.
La Agencia de Estándares Estadounidense (ASA), que se convertiría más tarde en el Instituto Nacional Estadounidense de Estándares (ANSI), publicó por primera vez el código ASCII en 1963. El ASCII publicado en 1963 tenía una flecha apuntando hacia arriba (↑) en lugar del circunflejo (^) y una flecha apuntando hacia la izquierda en lugar del guion bajo (_). La versión de 1967 añadió las letras minúsculas, cambió los nombres de algunos códigos de control y cambió de lugar los dos códigos de control ACK y ESC de la zona de letras minúsculas a la zona de códigos de control.
ASCII fue actualizado en consecuencia y publicado como ANSI X3.4-1968, ANSI X3.4-1977, y finalmente ANSI X3.4-1986.
Otros órganos de estandarización han publicado códigos de caracteres que son idénticos a ASCII. Estos códigos de caracteres reciben a menudo el nombre de ASCII, a pesar de que ASCII se define estrictamente solamente por los estándares ASA/ANSI:
- La Asociación Europea de Fabricantes de Ordenadores (ECMA) publicó ediciones de su clon de ASCII, ECMA-6 en 1965, 1967, 1970, 1973, 1983, y 1991. La edición de 1991 es idéntica a ANSI X3.4-1986.[4]
- La Organización Internacional de Estandarización (ISO) publicó su versión, ISO 646 (más tarde ISO/IEC 646) en 1967, 1972, 1983 y 1991. En particular, ISO 646:1972 estableció un conjunto de versiones específicas para cada país donde los caracteres de puntuación fueron reemplazados con caracteres no ingleses. ISO/IEC 646:1991 La International Reference Version es la misma que en el ANSI X3.4-1986.
- La Unión Internacional de Telecomunicaciones (ITU) publicó su versión de ANSI X3.4-1986, Recomendación ITU T.50, en 1992. A principios de la década de 1970 publicó una versión como Recomendación CCITT V.3.
- DIN publicó una versión de ASCII como el estándar DIN 66003 en 1974.
- El Grupo de Trabajo en Ingeniería de Internet (IETF) publicó una versión en 1969 como RFC 20, y estableció la versión estándar para Internet, basada en ANSI X3.4-1986, con la publicación de RFC 1345 en 1992.
- La versión de IBM de ANSI X3.4-1986 se publicó en la literatura técnica de IBM como página de códigos 367.
El código ASCII también está incluido en su probable relevo, Unicode, constituyendo los primeros 128 caracteres (o los 'más bajos').
Los caracteres de control ASCII
El código ASCII reserva los primeros 32 códigos (numerados del 0 al 31 en decimal) para caracteres de control: códigos no pensados originalmente para representar información imprimible, sino para controlar dispositivos (como impresoras) que usaban ASCII. Por ejemplo, el carácter 10 representa la función "nueva línea" (line feed), que hace que una impresora avance el papel, y el carácter 27 representa la tecla "escape" que a menudo se encuentra en la esquina superior izquierda de los teclados comunes.
El código 127 (los siete bits a uno), otro carácter especial, equivale a "suprimir" ("delete"). Aunque esta función se asemeja a otros caracteres de control, los diseñadores de ASCII idearon este código para poder "borrar" una sección de papel perforado (un medio de almacenamiento popular hasta la década de 1980) mediante la perforación de todos los agujeros posibles de una posición de carácter concreta, reemplazando cualquier información previa. Dado que el código 0 era ignorado, fue posible dejar huecos (regiones de agujeros) y más tarde hacer correcciones.
Muchos de los caracteres de control ASCII servían para marcar paquetes de datos, o para controlar protocolos de transmisión de datos (por ejemplo ENQuiry, con el significado: ¿hay alguna estación por ahí?, ACKnowledge: recibido o ", Start Of Header: inicio de cabecera, Start of TeXt: inicio de texto, End of TeXt: final de texto, etc.). ESCape y SUBstitute permitían a un protocolo de comunicaciones, por ejemplo, marcar datos binarios para que contuviesen códigos con el mismo código que el carácter de protocolo, y que el receptor pudiese interpretarlos como datos en lugar de como caracteres propios del protocolo.
Los diseñadores del código ASCII idearon los caracteres de separación para su uso en sistemas de cintas magnéticas.
Dos de los caracteres de control de dispositivos, comúnmente llamados XON y XOFF generalmente ejercían funciones de caracteres de control de flujo para controlar el flujo a hacia un dispositivo lento (como una impresora) desde un dispositivo rápido (como un ordenador), de forma que los datos no saturasen la capacidad de recepción del dispositivo lento y se perdiesen.
Los primeros usuarios de ASCII adoptaron algunos de los códigos de control para representar "metainformación" como final-de-línea, principio/final de un elemento de datos, etc. Estas asignaciones a menudo entraban en conflicto, así que parte del esfuerzo de convertir datos de un formato a otro comporta hacer las conversiones correctas de metainformación. Por ejemplo, el carácter que representa el final-de-línea en ficheros de texto varía con el sistema operativo. Cuando se copian archivos de un sistema a otro, el sistema de conversión debe reconocer estos caracteres como marcas de final-de-línea y actuar en consecuencia.
Actualmente los usuarios de ASCII usan menos los caracteres de control, (con algunas excepciones como "retorno de carro" o "nueva línea"). Los lenguajes modernos de etiquetas, los protocolos modernos de comunicación, el paso de dispositivos basados en texto a basados en gráficos, el declive de las teleimpresoras, las tarjetas perforadas y los papeles continuos han dejado obsoleta la mayoría de caracteres de control.
Binario Decimal Hex Abreviatura Repr AT Nombre/Significado 0000 0000 0 00 NUL ␀ ^@ Carácter Nulo 0000 0001 1 01 SOH ␁ ^A Inicio de Encabezado 0000 0010 2 02 STX ␂ ^B Inicio de Texto 0000 0011 3 03 ETX ␃ ^C Fin de Texto 0000 0100 4 04 EOT ␄ ^D Fin de Transmisión 0000 0101 5 05 ENQ ␅ ^E Consulta 0000 0110 6 06 ACK ␆ ^F Acuse de recibo 0000 0111 7 07 BEL ␇ ^G Timbre 0000 1000 8 08 BS ␈ ^H Retroceso 0000 1001 9 09 HT ␉ ^I Tabulación horizontal 0000 1010 10 0A LF ␊ ^J Salto de línea 0000 1011 11 0B VT ␋ ^K Tabulación Vertical 0000 1100 12 0C FF ␌ ^L De avance 0000 1101 13 0D CR ␍ ^M Retorno de carro 0000 1110 14 0E SO ␎ ^N Mayúsculas fuera 0000 1111 15 0F SI ␏ ^O En mayúsculas 0001 0000 16 10 DLE ␐ ^P Enlace de datos / Escape 0001 0001 17 11 DC1 ␑ ^Q Dispositivo de control 1 — oft. XON 0001 0010 18 12 DC2 ␒ ^R Dispositivo de control 2 0001 0011 19 13 DC3 ␓ ^S Dispositivo de control 3 — oft. XOFF 0001 0100 20 14 DC4 ␔ ^T Dispositivo de control 4 0001 0101 21 15 NAK ␕ ^U Confirmación negativa 0001 0110 22 16 SYN ␖ ^V Síncrono en espera 0001 0111 23 17 ETB ␗ ^W Fin de Transmision del Bloque 0001 1000 24 18 CAN ␘ ^X Cancelar 0001 1001 25 19 EM ␙ ^Y Finalización del Medio 0001 1010 26 1A SUB ␚ ^Z Substituto 0001 1011 27 1B ESC ␛ ^[ or ESC Escape 0001 1100 28 1C FS ␜ ^\ Separador de fichero 0001 1101 29 1D GS ␝ ^] Separador de grupo 0001 1110 30 1E RS ␞ ^^ Separador de registro 0001 1111 31 1F US ␟ ^_ Separador de unidad 0111 1111 127 7F DEL ␡ ^?, Delete o Backspace Eliminar Caracteres imprimibles ASCII
El código del carácter espacio, designa al espacio entre palabras, y se produce normalmente por la barra espaciadora de un teclado. Los códigos del 33 al 126 se conocen como caracteres imprimibles, y representan letras, dígitos, signos de puntuación y varios símbolos.
El ASCII de siete bits proporciona siete caracteres "nacionales" y, si la combinación concreta de hardware y software lo permite, puede utilizar combinaciones de teclas para simular otros caracteres internacionales: en estos casos un backspace puede preceder a un acento abierto o grave (en los estándares británico y americano, pero sólo en estos estándares, se llama también "opening single quotation mark"), una tilde o una "marca de respiración".
Binario Dec Hex Representación 0010 0000 32 20 espacio ( ) 0010 0001 33 21 ! 0010 0010 34 22 " 0010 0011 35 23 # 0010 0100 36 24 $ 0010 0101 37 25 % 0010 0110 38 26 & 0010 0111 39 27 ' 0010 1000 40 28 ( 0010 1001 41 29 ) 0010 1010 42 2A * 0010 1011 43 2B + 0010 1100 44 2C , 0010 1101 45 2D - 0010 1110 46 2E . 0010 1111 47 2F / 0011 0000 48 30 0 0011 0001 49 31 1 0011 0010 50 32 2 0011 0011 51 33 3 0011 0100 52 34 4 0011 0101 53 35 5 0011 0110 54 36 6 0011 0111 55 37 7 0011 1000 56 38 8 0011 1001 57 39 9 0011 1010 58 3A : 0011 1011 59 3B ; 0011 1100 60 3C < 0011 1101 61 3D = 0011 1110 62 3E > 0011 1111 63 3F ? Binario Dec Hex Representación 0100 0000 64 40 @ 0100 0001 65 41 A 0100 0010 66 42 B 0100 0011 67 43 C 0100 0100 68 44 D 0100 0101 69 45 E 0100 0110 70 46 F 0100 0111 71 47 G 0100 1000 72 48 H 0100 1001 73 49 I 0100 1010 74 4A J 0100 1011 75 4B K 0100 1100 76 4C L 0100 1101 77 4D M 0100 1110 78 4E N 0100 1111 79 4F O 0101 0000 80 50 P 0101 0001 81 51 Q 0101 0010 82 52 R 0101 0011 83 53 S 0101 0100 84 54 T 0101 0101 85 55 U 0101 0110 86 56 V 0101 0111 87 57 W 0101 1000 88 58 X 0101 1001 89 59 Y 0101 1010 90 5A Z 0101 1011 91 5B [ 0101 1100 92 5C \ 0101 1101 93 5D ] 0101 1110 94 5E ^ 0101 1111 95 5F _ Binario Dec Hex Representación 0110 0000 96 60 ` 0110 0001 97 61 a 0110 0010 98 62 b 0110 0011 99 63 c 0110 0100 100 64 d 0110 0101 101 65 e 0110 0110 102 66 f 0110 0111 103 67 g 0110 1000 104 68 h 0110 1001 105 69 i 0110 1010 106 6A j 0110 1011 107 6B k 0110 1100 108 6C l 0110 1101 109 6D m 0110 1110 110 6E n 0110 1111 111 6F o 0111 0000 112 70 p 0111 0001 113 71 q 0111 0010 114 72 r 0111 0011 115 73 s 0111 0100 116 74 t 0111 0101 117 75 u 0111 0110 118 76 v 0111 0111 119 77 w 0111 1000 120 78 x 0111 1001 121 79 y 0111 1010 122 7A z 0111 1011 123 7B { 0111 1100 124 7C | 0111 1101 125 7D } 0111 1110 126 7E ~ Rasgos estructurales
- Los dígitos del 0 al 9 se representan con sus valores prefijados con el valor 0011 en binario (esto significa que la conversión BCD-ASCII es una simple cuestión de tomar cada unidad bcd y prefijarla con 0011).
- Las cadenas de bits de las letras minúsculas y mayúsculas sólo difieren en un bit, simplificando de esta forma la conversión de uno a otro grupo.
Otros nombres para ASCII
La RFC 1345 (publicada en junio de 1992) y el registro IANA de códigos de caracteres, reconocen los siguientes nombres alternativos para ASCII para su uso en Internet.
- ANSI_X3.4-1968 (nombre canónico)
- ANSI_X3.4-1986
- ASCII
- US-ASCII (nombre MIME recomendado)
- us
- ISO646-US
- ISO_646.irv:1991
- iso-ir-6
- IBM367
- cp367
- csASCII
De estos, sólo los nombres "US-ASCII" y "ASCII" se usan ampliamente. A menudo se encuentran en el parámetro de "código de caracteres" opcional en la cabecera Content-Type de algunos mensajes MIME, en el elemento equivalente "meta" de algunos documentos HTML, y en la parte de declaración de codificación de carácter de la cabecera de algunos documentos XML.
Variantes de ASCII
A medida que la tecnología informática se difundió a lo largo del mundo, se desarrollaron diferentes estándares y las empresas desarrollaron muchas variaciones del código ASCII para facilitar la escritura de lenguas diferentes al inglés que usaran alfabetos latinos. Se pueden encontrar algunas de esas variaciones clasificadas como "ASCII Extendido", aunque en ocasiones el término se aplica erróneamente para cubrir todas las variantes, incluso las que no preservan el conjunto de códigos de caracteres original ASCII de siete bits.
La ISO 646 (1972), el primer intento de remediar el sesgo pro-inglés de la codificación de caracteres, creó problemas de compatibilidad, pues también era un código de caracteres de 7 bits. No especificó códigos adicionales, así que reasignó algunos específicamente para los nuevos lenguajes. De esta forma se volvió imposible saber en qué variante se encontraba codificado el texto, y, consecuentemente, los procesadores de texto podían tratar una sola variante.
La tecnología mejoró y aportó medios para representar la información codificada en el octavo bit de cada byte, liberando este bit, lo que añadió otros 128 códigos de carácter adicionales que quedaron disponibles para nuevas asignaciones. Por ejemplo, IBM desarrolló páginas de código de 8 bits, como la página de códigos 437, que reemplazaba los caracteres de control con símbolos gráficos como sonrisas, y asignó otros caracteres gráficos adicionales a los 128 bytes superiores de la página de códigos. Algunos sistemas operativos como DOS, podían trabajar con esas páginas de código, y los fabricantes de ordenadores personales incluyeron soporte para dichas páginas en su hardware.
Los estándares de ocho bits como ISO 8859 y Mac OS Roman fueron desarrollados como verdaderas extensiones de ASCII, dejando los primeros 127 caracteres intactos y añadiendo únicamente valores adicionales por encima de los 7-bits. Esto permitió la representación de un abanico mayor de lenguajes, pero estos estándares continuaron sufriendo incompatibilidades y limitaciones. Todavía hoy, ISO-8859-1 y su variante Windows-1252 (a veces llamada erróneamente ISO-8859-1) y el código ASCII original de 7 bits son los códigos de carácter más comúnmente utilizados.
Unicode y Conjunto de Caracteres Universal (UCS) ISO/IEC 10646 definen un conjunto de caracteres mucho mayor, y sus diferentes formas de codificación han empezado a reemplazar ISO 8859 y ASCII rápidamente en muchos entornos. Mientras que ASCII básicamente usa códigos de 7-bits, Unicode y UCS usan "code points" o apuntadores relativamente abstractos: números positivos (incluyendo el cero) que asignan secuencias de 8 o más bits a caracteres. Para permitir la compatibilidad, Unicode y UCS asignan los primeros 128 apuntadores a los mismos caracteres que el código ASCII. De esta forma se puede pensar en ASCII como un subconjunto muy pequeño de Unicode y UCS. La popular codificación UTF-8 recomienda el uso de uno a cuatro valores de 8 bits para cada apuntador, donde los primeros 128 valores apuntan a los mismos caracteres que ASCII. Otras codificaciones de caracteres como UTF-16 se parece a ASCII en cómo representan los primeros 128 caracteres de Unicode, pero tienden a usar 16 a 32 bits por carácter, así que requieren de una conversión adecuada para que haya compatibilidad entre ambos códigos de carácter.
La palabra ASCIIbético (o, más habitualmente, la palabra "inglesa" ASCIIbetical) describe la ordenación según el orden de los códigos ASCII en lugar del orden alfabético.[5]
La abreviatura ASCIIZ o ASCIZ se refiere a una cadena de caracteres terminada en cero (del inglés "zero").
Es muy normal que el código ASCII sea embebido en otros sistemas de codificación más sofisticados y por esto debe tenerse claro cual es papel del código ASCII en la tabla o mapa de caracteres de un ordenador.
Arte ASCII
_ _ ____ ____ ___ ___ __ _ _ __| |_ ____ /_\ / ___| / ___|_ _|_ _| / _` | '__| __|/ __ \ //_\\ \___ \| | | | | | | (_| | | | |_| ___/ / ___ \ ___) | |___ | | | | \__,_|_| \__|\____) /_/ \_\____/ \____|___|___|El código de caracteres ASCII es el soporte de una disciplina artística minoritaria, el arte ASCII, que consiste en la composición imágenes mediante caracteres imprimibles ASCII. El efecto resultante ha sido comparado con el puntillismo, pues las imágenes producidas con esta técnica generalmente se aprecian con más detalle al ser vistas a distancia. El arte ASCII empezó siendo un arte experimental, pero pronto se popularizó como recurso para representar imágenes en soportes incapaces de procesar gráficos, como teletipos, terminales, correos electrónicos o algunas impresoras.
Aunque se puede componer arte ASCII manualmente mediante un editor de textos, también se pueden convertir automáticamente imágenes y vídeos en ASCII mediante software, como la librería Aalib (de licencia libre), que ha alcanzado cierta popularidad. Aalib está soportada por algunos programas de diseño gráfico, juegos y reproductores de vídeo.
Véase también
- Archivos de texto y archivos binarios
- EBCDIC
- ASCII extendido
- ISCII
- ISO/IEC 646
- ISO 8859
- Juegos ASCII
Variantes ASCII de ordenadores específicos
Referencias
Generales
- Unicode.org Cuadro Unicode de la zona ASCII
- Tom Jennings (29 de octubre de 2004). Historia anotada de los códigos de caracteres Accedido 17 de diciembre de 2005.
Al pie
- ↑ Nombres de Dominio Internacionalizados - Glosario, Internet Corporation for Assigned Names and Numbers (ICANN). Consultado el 19-11-2008.
- ↑ Organización Internacional para la Estandarización (1 de diciembre de 1975). "El conjunto de caracteres de ISO 646". Internet Assigned Numbers Authority Registry. Versión estadounidense: [1]. Accedido el 7 de agosto de 2005.
- ↑ Internet Assigned Numbers Authority (28 de enero de 2005). "Códigos de caracteres". Accedido el 7 de agosto de 2005.
- ↑ ECMA International (diciembre de 1991). Standard ECMA-6: 7-bit Coded Character Set, 6th edition Accedido el 17 de diciembre de 2005.
- ↑ Jargon File. ASCIIbetical. Accedido el 17 de diciembre de 2005.
Enlaces externos
- Herramienta online que muestra los caracteres ASCII y sus conversiones a otros sistemas numéricos.
Categorías:- Codificación de caracteres
- Protocolos y formatos de nivel de presentación
-


Wikimedia foundation. 2010.