- Predicción de genes
-
Predicción de genes

Los mecanismos o procesos de predicción de genes (gene prediction en inglés, o también gene finding, literalmente descubrimiento de genes) son aquellos que, dentro del área de la biología computacional, se utilizan para la identificación algorítmica de trozos de secuencia, usualmente ADN genómico, y que son biológicamente funcionales. Esto, especialmente, incluye los genes codificantes de proteínas, pero también podría incluir otros elementos funcionales tales como genes ARN y regiones reguladoras. La identificación de genes es uno de los primeros y más importantes pasos para entender el genoma de una especie una vez ha sido secuenciado.
Contenido
Antecedentes
En 1986, y ante el avance en la secuenciación del material genético de organismos más sencillos , el Departamento de Energía de los EE.UU. anunció la iniciativa que se conocería como Proyecto Genoma Humano y que impulsaría de forma muy importante los avances en la genómica y especialidades vinculadas (tanto del ámbito biológico como del tecnológico) que hemos registrado en los últimos años.[1] Este proyecto potenciaba un proceso empezado unos diez años antes con las primeras secuenciaciones del genoma de organismos elementales, y su objetivo era el conocimiento de la secuencia completa de nucleótidos del conjunto del ADN del ser humano. Fue culminado en 2003, y en su éxito tuvo mucho que ver la bioinformática en general y las aplicaciones de alineamiento de secuencias biológicas en particular.[2] Pero, tanto de forma paralela al proceso de secuenciación completa del ADN, como con posterioridad al punto final del proyecto (marcado por la obtención de la secuencia de alta calidad completada en abril de 2003), una tarea tan importante como la identificación de la estructura íntima del ADN se llevaba a cabo tanto sobre el genoma humano como sobre el de otros organismos: la identificación de los genes responsables de la codificación para la producción de proteínas y que, entre otros objetivos (que ya no se circunscribían a una básica clasificación de material genético en organismos inferiores), podía suponer la identificación precisa de las causas de multitud de enfermedades así como la obtención de conocimiento fundamental para tratarlas.[1] Es en este campo particular (aunque no exclusivo) donde los métodos de descubrimiento automático de genes han tenido, y siguen teniendo, una aplicación directa y trascendente. No obstante, es de reseñar que en cualquier tarea de predicción y análisis automatizado de genes, las referencias definitivas son las dispuestas por los biólogos expertos en el área, quienes deben confirmar, validar y completar el descubrimiento automático y la anotación última de los genes.
En sus primeras etapas, la predicción de genes se basaba en una laboriosa experimentación sobre células y organismos vivos. El análisis estadístico de los ratios de recombinación homóloga de multitud de genes diferentes podría determinar su orden en un determinado cromosoma, y la información obtenida de tales experimentos se combinaría para crear un mapa genético, especificando la localización aproximada relativa entre genes conocidos. Poco a poco, y en un periodo de aproximadamente veinte años, el conocimiento que se iba acumulando sobre vinculaciones génicas por homología, de un lado, y la identificación de determinadas características comunes (señales funcionales, patrones, periodicidades) en las secuencias codificantes, por otro, permitió (junto con los avances y generalización de los sistemas de tratamiento de la información) ir perfeccionando el análisis automatizado de un determinado genoma. Hoy, con una exhaustiva secuencia del genoma, además de potentes recursos computacionales a disposición de la comunidad investigadora, la predicción de genes ha sido redefinida, en gran parte, como un problema computacional.
En la actualidad, la determinación de si una secuencia es funcional debe distinguirse de la determinación de la función del gen o de su producto. Esta última todavía necesita experimentación in vivo a través del silenciamiento de genes y otros ensayos, aunque las fronteras de la investigación bioinformática están haciendo cada vez más posible la predicción de la función de un gen basándose únicamente en su secuencia.
Aproximaciones extrínsecas
En sistemas de predicción de genes basados en evidencias, en el genoma objetivo se buscan secuencias que sean similares a la evidencia externa, que toma la forma de una secuencia conocida de un ARN mensajero (ARNm) o producto proteico. Dada una secuencia de ARNm, es trivial derivar una única secuencia genómica de ADN desde la cual haya tenido que ser transcrita. Dada una secuencia de proteína, se puede derivar por traducción reversa del código genético una familia de posibles secuencias de ADN codificante. Una vez que las secuencias de ADN candidatas han sido determinadas, es un problema algorítmico relativamente sencillo el buscar eficientemente un genoma objetivo para las coincidencias, totales o parciales, exactas o inexactas. BLAST es un sistema ampliamente utilizado para este propósito.
Un alto grado de similitud con un ARN mensajero conocido, o con un producto proteico, es una fuerte evidencia de que una región del genoma en cuestión es un gen codificante de proteína. Sin embargo, aplicar esta aproximación sistemáticamente requiere una exhaustiva secuenciación de ARNm y productos proteicos. No sólo esto resulta caro, sino que en organismos complejos sólo un subconjunto de todos los genes del genoma del organismo se expresan en un determinado momento, lo que significa que la evidencia extrínseca para muchos genes no está accesible fácilmente en cualquier cultivo de una única célula. Así, para recoger esta evidencia para la mayoría o para todos los genes en un organismo complejo, deben ser estudiadas varios centenares o miles de tipos de células diferentes, lo que representa en sí dificultades añadidas. Algunos genes humanos, por ejemplo, podrían sólo expresarse durante su desarrollo como embrión o feto, lo que dificultaría su estudio por razones éticas.
A pesar de estas dificultades, se han generado unas exhaustivas bases de datos de transcripciones y secuencias de proteínas tanto para el ser humano como para otros organismos modelo importantes en biología, como los ratones o la levadura. Por ejemplo la base de datos RefSeq contiene transcripciones y secuencias proteicas de muchas especies diferentes, y el sistema Ensembl proyecta intensivamente esta evidencia al ser humano y a bastantes otros genomas. Sin embargo, es probable que ambas bases de datos estén incompletas, y que contengan pequeñas, pero significativas, cantidades de datos erróneos.
Aproximaciones Ab Initio
Dado el gasto y la dificultad inherentes a la obtención de evidencias extrínsecas para muchos genes, es también necesario recurrir a la predicción de genes ab initio, en la cual se busca, sistemáticamente y de forma exclusiva en la secuencia genómica de ADN, ciertos signos reveladores de genes codificantes de proteínas. Estos signos pueden ser categorizados, en líneas generales, bien como señales (secuencias específicas que indican la presencia cercana de un gen), bien como contenido (propiedades estadísticas de la propia secuencia codificante). El término predicción de la expresión “predicción de genes ab initio” queda precisamente caracterizado como tal puesto que la evidencia externa es generalmente necesaria para establecer de forma concluyente que un supuesto gen es funcional.
 Esquema de un marco abierto de lectura, que incluye los codones de inicio (o start) y de parada (o stop).
Esquema de un marco abierto de lectura, que incluye los codones de inicio (o start) y de parada (o stop).
En los genomas de los organismos procariotas, los genes tienen secuencias promotoras (señales) específicas y relativamente bien conocidas, como la caja Pribnow (Pribnow box) y los sitios de unión de los factores de transcripción, que son fácilmente identificables de forma sistemática. Además, la secuencia codificante para una proteína se presenta como un marco abierto de lectura (open reading frame, ORF) contiguo, que típicamente mide varios centenares o miles de pares de bases. Las estadísticas de los codones de parada son tales que encontrar un marco abierto de lectura de esa longitud es prácticamente un signo informativo: puesto que 3 de los 64 posibles codones en el código genético son codones de parada, podría esperarse un codón de parada, aproximadamente, por cada 20-25 codones, o 60-75 pares de bases, en una secuencia aleatoria. Además, el ADN codificante tiene ciertas periodicidades y otras propiedades estadísticas que son fáciles de detectar en una secuencia de esta longitud. Estas características convierten la predicción de genes en procariotas en algo relativamente sencillo, y los sistemas bien diseñados son capaces de alcanzar altos niveles de precisión.
La predicción de genes en organismos eucariotas, especialmente en organismos tan complejos como el ser humano, es considerablemente más desafiante por varias razones. Primero, el promotor y otras señales regulatorias en estos genomas son más complicadas y menos comprendidas que en los procariotas, haciéndolas más complicadas de reconocer fidedignamente. Dos ejemplos clásicos de señales identificadas por los descubridores de genes eucariotas son las islas CpG y los sitios de unión para una cola poli-A.
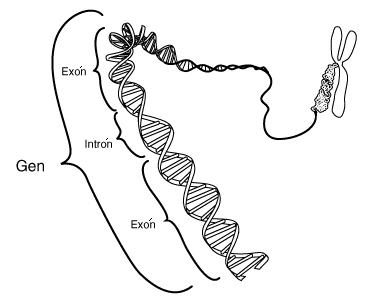
Segundo, los mecanismos de splicing (‘’empalme’’, y también ‘’ayuste’’, en alguna literatura en castellano) empleado por las células eucarióticas suponen que una determinada secuencia codificante (a proteínas) en el genoma es dividida en diversas partes (exones), separadas por secuencias no codificantes (intrones). (Los sitios de empalme son, en sí mismos, otra señal para cuya identificación están diseñados a menudo los descubridores de genes eucariotas.) Un gen codificante en los humanos puede dividirse en una docena de exones, cada uno de ellos menor de doscientos pares de bases de longitud, y algunos tan cortos como veinte o treinta pares. Es, por lo tanto, mucho más difícil detectar periodicidades u otras propiedades conocidas del ADN codificante en los eucariotas.
Los predictores avanzados de genes para genomas tanto procariotas como eucariotas, usan típicamente complejos modelos probabilísticos, como los modelos ocultos de Márkov, para combinar información conseguida de una variedad de diferentes medidas de señal y contenido. El sistema GLIMMER es un identificador de genes ampliamente usado y muy preciso para organismos procariotas. GeneMark es otra aproximación popular. Los predictores de genes ‘’ab initio’’, en comparación, han conseguido sólo éxitos limitados. Ejemplos notables de estos son los programas GENSCAN y geneid. Unos pocos programas, como CONTRAST usan aproximaciones de aprendizaje automático, como máquinas de soporte vectorial, para una eficaz predicción de genes.
Otras señales
Entre las señales utilizadas para la predicción de genes están las estadísticas resultantes del análisis estadístico de sub-secuencias como k-meros (n-gramas de secuencias de ácidos nucléicos o aminoácidos), la transformada de Fourier de un ADN pseudo-numéricamente codificado, los parámetros de una Z-curva (curva tridimensional relacionada biunívocamente con una determinada secuencia de ADN), y ciertas características de su recorrido.[3]
Se ha sugerido que otras señales, aparte de aquellas directamente detectables en las secuencias, podrían mejorar la predicción de genes. Por ejemplo, se ha informado sobre el papel de la estructura secundaria en la identificación de motivos reguladores.[4] También se ha sugerido que la predicción de la estructura secundaria del ARN ayuda a la predicción de los sitios de empalme.[5] [6] [7] [8]
Aproximaciones por Genómica Comparativa
Según se van secuenciando los genomas completos de muchas especies diferentes, encontramos en el enfoque por genómica comparativa una prometedora dirección en la investigación actual sobre predicción de genes. Esta se basa en el principio de que las fuerzas de la selección natural causan que los genes y otros elementos funcionales experimenten las mutaciones a un ritmo menor que el experimentado en el resto del genoma, ya que las mutaciones en los elementos funcionales afectan de forma negativa al organismo con mayor probabilidad que las mutaciones en cualquier otra parte. Así, los genes pueden ser detectados comparando los genomas de especies vinculadas para detectar esta presión evolutiva para la conservación. Esta aproximación se aplicó inicialmente sobre los genomas del ratón y del ser humano, usando programas tales como SLAM, SGP y Twinscan/N-SCAN.
La predicción de genes comparativa puede usarse, también, para proyectar anotaciones de alta calidad de un genoma a otro. Como ejemplos notables se encuentran Projector, GeneWise y GeneMapper. Estas técnicas juegan ahora un papel central en la anotación de todos los genomas.
Referencias
- ↑ a b U.S. Dpt. of Energy Genome Research Programs (Agosto de 2006). «Genomics and its Impact on Science and Society» (pdf).
- ↑ U.S. Dpt. of Energy Genome Research Programs (2007). «Human Genome Project Information: Bioinformatics» (html).
- ↑ Saeys Y, Rouzé P, Van de Peer Y (2007). «In search of the small ones: improved prediction of short exons in vertebrates, plants, fungi and protists» Bioinformatics. Vol. 23. n.º 4. pp. 414-420. DOI 10.1093/bioinformatics/btl639.
- ↑ Hiller M, Pudimat R, Busch A, Backofen R (2006). «Using RNA secondary structures to guide sequence motif finding towards single-stranded regions» Nucleic Acids Res. Vol. 34. n.º 17. pp. e117. Entrez PubMed 16987907.
- ↑ Patterson DJ, Yasuhara K, Ruzzo WL (2002). «Pre-mRNA secondary structure prediction aids splice site prediction» Pac Symp Biocomput. pp. 223-234. Entrez PubMed 11928478.
- ↑ Marashi SA, Goodarzi H, Sadeghi M, Eslahchi C, Pezeshk H (2006). «Importance of RNA secondary structure information for yeast donor and acceptor splice site predictions by neural networks» Comput Biol Chem. Vol. 30. n.º 1. pp. 50-57. Entrez PubMed 16386465.
- ↑ Marashi SA, Eslahchi C, Pezeshk H, Sadeghi M (2006). «Impact of RNA structure on the prediction of donor and acceptor splice sites» BMC Bioinformatics. Vol. 7. pp. 297. Entrez PubMed 16772025.
- ↑ Rogic, S (2006). "The role of pre-mRNA secondary structure in gene splicing in Saccharomyces cerevisiae". PhD Dissertation, University of British Columbia.
Enlaces externos
- genefinding, repositorio de software y recursos para predicción de genes
- Bibliografía sobre reconocimiento computacional de genes, por Wentian Li
- geneid, software eficiente basado en el reconocimiento de señales funcionales
- SGP2, que combina geneid con tblastx
- Glimmer está orientado al descubrimiento de genes en bacterias y virus
- GlimmerHMM utiliza Glimmer bajo modelos ocultos de Márkov generalizados
- GeneMapper, software que transfiere anotaciones de genomas bien referenciados a otros en desarrollo
- GenomeThreader es una herramienta para predecir la estructura génica
- GENSCAN: servidor on-line del MIT para análisis de genes sobre ADN
- Twinscan/N-SCAN, software y servidor de la Washington University
- CHEMGENOME analiza genomas mediante propiedades físico-químicas
- Software GeneMark con diferentes versiones para predicción de genes en procariotas y eucariotas
Categoría: Bioinformática
Wikimedia foundation. 2010.