- Bigrama
-
Bigrama
Los Bigramas son grupos de dos letras, dos sílabas, o dos palabras, y son utilizados comúnmente como base para el simple análisis estadístico de texto. Se utilizan en uno de los más exitosos modelos de lenguaje para el reconocimiento de voz.[1] Se trata de un caso especial del N-grama.
Los Bigramas ayudan a proporcionar la probabilidad condicional de una palabra dada la palabra precedente, cuando la relación de la probabilidad condicional se aplica:
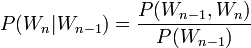
Es decir, la probabilidad P() de una palabra Wn < / math > dadalapalabraprecedente < math > Wn − 1 es igual a la probabilidad de su bigrama, o la co-ocurrencia de las dos palabras P(Wn − 1,Wn), dividido por la probabilidad de que la palabra precedente.
References
- ↑ Michael Collins. A new statistical parser based on bigram lexical dependencies. In Proceedings of the 34th Annual Meeting of the Association of Computational Linguistics, Santa Cruz, CA. 1996. pp.184-191.
Véase también
Categorías: Procesamiento de lenguaje natural | Lingüística computacional | Reconocimiento de voz | Bioinformática
Wikimedia foundation. 2010.